· Jessy Huang · Engineering · 29 min read
缓存不是 Redis:从 Go 后端到 AI Agent,业务系统里的缓存体系怎么设计
用业务场景讲清 Go 本地缓存、Redis、Prompt Caching、RAG 缓存、MQ、MySQL 一致性和游戏状态缓存。
很多后端系统的性能优化,都是从一句非常熟悉的话开始的:
这个接口有点慢,加个 Redis 吧。
这句话不能说错。
但它也很容易把人带沟里。因为业务要解决的问题从来不是“怎么用 Redis”,而是:
怎么让系统更快、更稳、更便宜、出问题还能恢复。
Redis 只是工具箱里最常用的那把扳手。
有时候你需要的是 Go 进程内缓存,有时候是 singleflight,有时候是 Eino / LangChain 的 memory 和 checkpoint,有时候是 OpenAI / Anthropic 的 Prompt Caching,有时候是向量库,有时候是 MQ,有时候老老实实让 MySQL 当裁判。
如果所有问题都用 Redis 解决,最后 Redis 会变成一个又当收银员、又当仓库、又当会计、又当消防员的同事。这样的同事一般不是全能,是快离职了。
所以这篇文章换个角度讲缓存:
我们不是为了使用 Redis 才设计缓存,而是为了业务目标选择合适的缓存层。
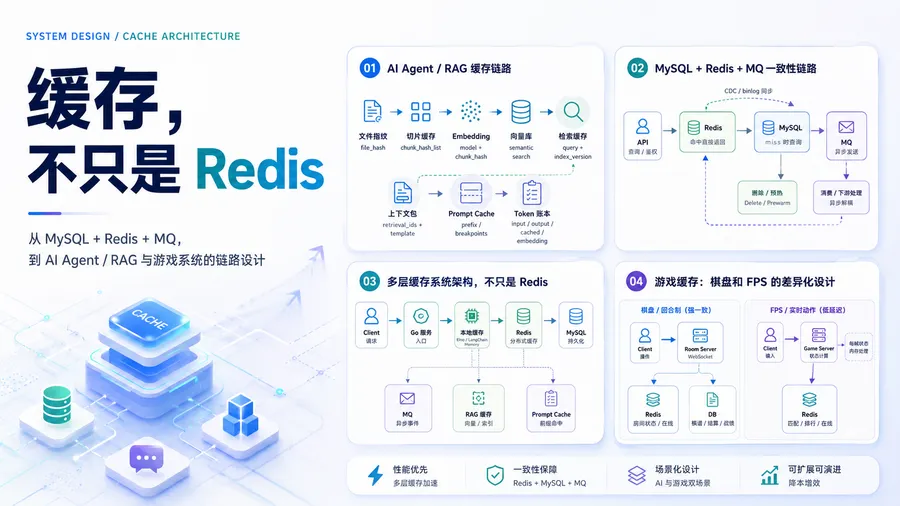
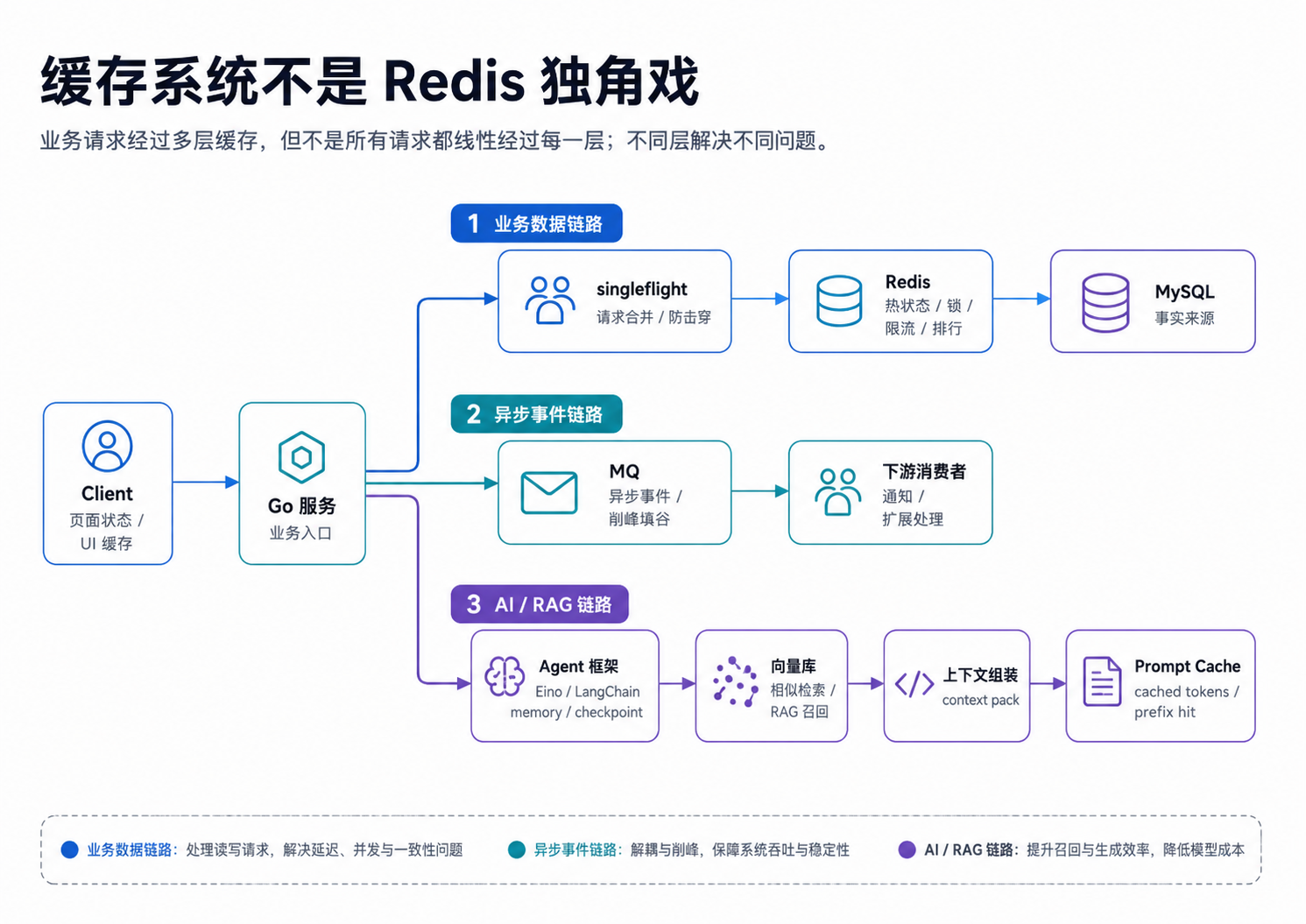
一、先画地图:缓存系统不是单层结构
真实业务里,一个请求往往会穿过很多层缓存。
比如一个 AI Agent 请求:
- 浏览器里保留了当前会话 UI 状态
- Go 服务用本地缓存挡住热点配置
- Agent 框架保存 checkpoint,方便中断恢复
- Redis 记录任务状态、限流、工具结果
- RAG 系统缓存文件切片和 embedding
- 模型厂商命中 Prompt Cache
- MySQL 保存最终任务结果和账单
- MQ 异步发通知、写审计、刷新下游缓存
如果你只问“Redis 怎么用”,就像只盯着厨房里的锅,却忘了还有冰箱、案板、菜单、收银系统和消防通道。
更合理的思考方式是:
| 层级 | 负责什么 | 典型工具 | 命中指标 | 主要风险 |
|---|---|---|---|---|
| 客户端缓存 | UI 状态 静态资源 棋盘本地状态 | Browser / App Memory HTTP Cache LocalStorage / IndexedDB | 本地命中率 页面加载时间 交互延迟 | 旧状态 越权数据 缓存未及时失效 |
| Go 本地缓存 | 进程内热点 配置缓存 请求合并 / 回源保护 | map + mutexsync.MapLRUsingleflight | local hit 本地命中率 回源次数 | 多实例不一致 进程重启丢失 过期策略不清晰 |
| 框架缓存 | Agent Memory Checkpoint Retriever 状态 多轮会话状态 | Eino LangChain LangGraph | resume rate memory hit checkpoint 恢复率 | 存储后端不可靠 状态恢复失败 上下文污染 |
| Redis 服务缓存 | 热数据 分布式锁 限流 排行榜 任务状态 | Redis String Hash ZSet Stream Lua Script | Redis hit rate P99 延迟 慢查询 内存使用率 | 热 key 缓存雪崩 缓存击穿 Redis 故障 |
| RAG 缓存 | 文件切片 Embedding 检索结果 上下文包复用 | Redis 向量库 对象存储 Embedding Cache | chunk hit embedding hit retrieval hit | 索引版本不一致 权限范围缓存错误 旧向量未失效 |
| Prompt Cache | 模型输入前缀 工具定义 系统提示词 长上下文稳定部分 | OpenAI Anthropic 模型厂商缓存能力 | cached tokens cache read tokens prefix hit rate | 只缓存稳定前缀 不缓存业务结果 动态内容影响命中 |
| MQ / 事件缓存 | 异步任务 削峰填谷 事件分发 缓存失效通知 | Kafka RabbitMQ RocketMQ Redis Streams | backlog 消费延迟 失败率 死信数量 | 重复消费 消息乱序 消息积压 消费者失败 |
| 数据库 | 最终事实 交易数据 审计记录 强一致数据 | MySQL PostgreSQL | 事务成功率 查询延迟 慢 SQL 锁等待 | 把缓存误当真相 缓存覆盖真实数据 主从延迟 |
这张表的重点不是“工具很多”,而是:
每一层缓存都有自己的命中定义、失效方式和责任边界。
Redis 很重要,但它不是整套缓存系统的名字。
二、Go 本身能解决什么:不要每个热点都先冲向 Redis
很多 Go 服务的缓存问题,第一层其实不需要 Redis。
比如:
- 配置每 30 秒刷新一次
- 某个 feature flag 每个请求都要读
- 同一个热点 key 在一瞬间被 1000 个 goroutine 同时回源
- 单实例内重复计算一个昂贵结果
这些可以先在 Go 进程内解决。
1. 本地缓存适合什么
本地缓存适合:
- 数据很小
- 可以短暂不一致
- 每个实例都能自己刷新
- 丢了可以重建
- 访问频率极高
比如系统配置、静态字典、短期权限模板。
它的好处是没有网络往返。Redis 再快,也要过网络;Go 本地 map 命中就是进程内完成。
但本地缓存也有边界:
- 多实例之间不一致
- 无法全局限流
- 无法做跨实例锁
- 进程重启就丢
- 容量和淘汰策略要自己控制
所以本地缓存常常是 Redis 前面的一层保护,而不是 Redis 的替代品。
请求
-> Go 本地缓存
-> Redis
-> MySQL / 外部服务2. singleflight 解决什么
缓存击穿时,最怕的不是一次 miss,而是同一个 key 同时 miss。
比如首页推荐配置过期,1000 个请求同时发现 Redis 没有,然后一起冲 MySQL。数据库看到这阵仗,大概会想:“我只是个数据库,不是演唱会安保。”
Go 里可以用 singleflight 合并同一个 key 的回源:
var group singleflight.Group
func GetProduct(ctx context.Context, id int64) (*Product, error) {
key := fmt.Sprintf("product:%d", id)
if p, ok := localCache.Get(key); ok {
return p, nil
}
v, err, _ := group.Do(key, func() (any, error) {
if p, ok := redisGetProduct(ctx, key); ok {
localCache.Set(key, p, 3*time.Second)
return p, nil
}
p, err := mysqlGetProduct(ctx, id)
if err != nil {
return nil, err
}
redisSetProduct(ctx, key, p, jitter(10*time.Minute))
localCache.Set(key, p, 3*time.Second)
return p, nil
})
if err != nil {
return nil, err
}
return v.(*Product), nil
}这里的设计点是:
- 本地缓存挡住极短时间的热点重复读
- Redis 承接跨实例共享缓存
singleflight合并单实例内同 key 回源- MySQL 只在必要时被访问
- TTL 加抖动,避免集体过期
这就是“为了业务使用工具”,不是“为了 Redis 使用 Redis”。
三、AI Agent:Prompt Cache、Agent Cache、Redis Cache 不是一回事
AI Agent 系统特别容易把缓存概念搅在一起。
比如你做一个“代码仓库分析 Agent”:
- system prompt 很长
- tools 很多
- RAG 会塞一堆文件片段
- Agent 会调用 GitHub、CI、日志系统
- 用户可能重复问类似问题
- 任务可能跑一半中断
这时候至少有三种缓存:
| 缓存 | 谁提供 | 缓存内容 | 命中方式 | 解决的问题 |
|---|---|---|---|---|
| Prompt Cache | OpenAI / Anthropic | 模型输入前缀、工具定义、长上下文 | prefix / breakpoint | 降低模型 prefill 成本和延迟 |
| Agent Cache | Eino / LangChain / 应用 | checkpoint、memory、工具结果 | runID、tool args hash、semantic key | 恢复执行、减少重复工具调用 |
| Redis Cache | 应用基础设施 | 状态、限流、幂等、任务进度 | Redis key | 跨实例共享热状态 |
1. Provider Prompt Cache 怎么用
OpenAI Prompt Caching 的关键点:
- 对近期模型自动生效
- 1024 tokens 以上开始有缓存收益
- 命中要求完全相同的 prompt 前缀
- 静态内容放前面,动态内容放后面
- usage 里看
cached_tokens prompt_cache_key可以帮助相同前缀请求路由到更容易命中的位置
Anthropic Prompt Caching 的关键点:
- 可以用 top-level
cache_control自动缓存 - 也可以给内容块设置 explicit cache breakpoints
- prefix 包括 tools、system、messages
- 最多 4 个 cache breakpoints
- usage 里区分
cache_read_input_tokens、cache_creation_input_tokens、input_tokens
所以 Agent prompt 应该这样组织:
稳定工具定义
稳定系统指令
稳定输出格式
相对稳定的 RAG 背景材料
动态用户问题
动态工具返回不要把时间戳、随机 request id、用户临时参数塞在最前面。否则每次前缀都变,Prompt Cache 就像门口的熟客通道,每次你都换脸进门。
2. Agent 自己怎么缓存
Provider cache 只解决模型前缀,不解决业务过程。
Agent 自己要缓存:
- 工具调用结果
- checkpoint
- 中间状态
- 会话摘要
- 用户额度
- 外部 API 返回
Eino 的 Runner 支持 CheckPointStore,示例里用内存 store,但真实服务可以用 Redis 这类分布式 store。LangChain / LangGraph 则有 memory、semantic search、retriever 这类能力,可以把相关记忆或文档片段检索出来拼进 prompt。
Redis 里的 key 可以这样设计:
agent:checkpoint:{tenant}:{run_id}
agent:task:{task_id}:status
agent:tool:{tenant}:{tool}:{args_hash}:{permission_version}
agent:quota:{tenant}:{user_id}:{yyyymmdd}
agent:summary:{session_id}:{summary_version}解决方案要点:
args_hash必须基于规范化参数生成,比如 JSON canonicalize 后 hash。- 缓存 key 要带租户、用户或权限版本,避免跨权限命中。
- 工具结果 TTL 要按数据变化速度定。CI 日志可以稍久,搜索结果要短,权限结果更谨慎。
- checkpoint 要有清理策略。不要让跑失败的 Agent 在 Redis 里变成考古遗址。
- token 账本要分开记录 provider token、embedding token、tool 调用次数、Redis 命中。
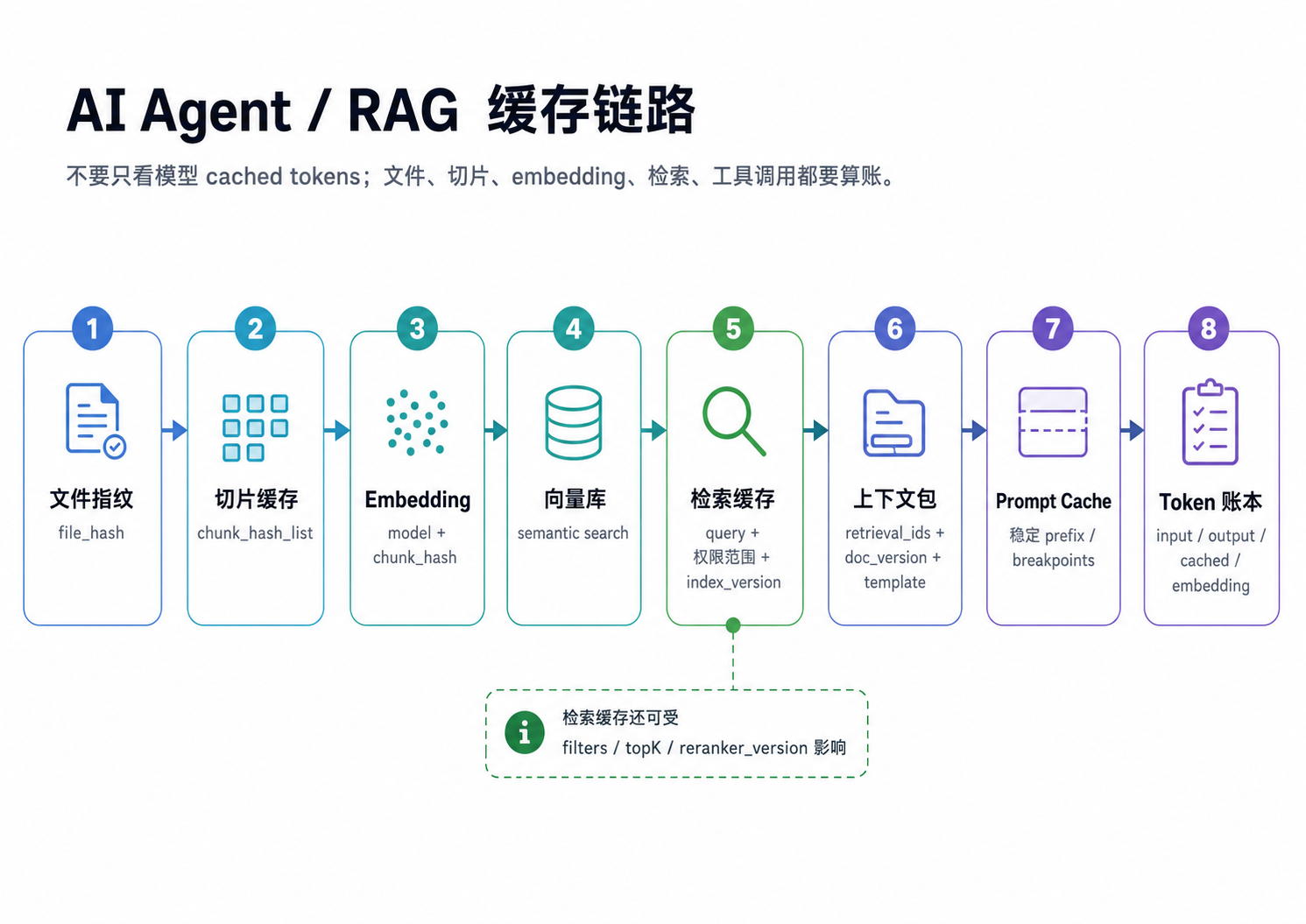
四、RAG:缓存的不只是答案,而是处理链路
RAG 最容易浪费钱的地方不是最终回答,而是重复处理文档。
一个 PDF 从上传到回答,中间有很多节点:
上传文件
-> 计算 file_hash
-> 解析文本
-> 切 chunk
-> 计算 chunk_hash
-> 调 embedding 模型
-> 写向量库
-> query 检索
-> rerank
-> 拼 context
-> 调 LLM如果用户重复上传同一份文档,或者同一个知识库反复构建索引,你不应该每次都重新 embedding。
1. 文件级缓存
key:
rag:file:{tenant}:{file_sha256}value:
{
"parse_status": "done",
"parser_version": "pdf-v3",
"chunker_version": "semantic-v2",
"chunk_hashes": ["...", "..."],
"created_at": 1782600000
}作用:
- 判断文件是否处理过
- 避免重复解析
- 关联 chunk 列表
2. Chunk 和 Embedding 缓存
embedding 缓存要带模型版本:
rag:embedding:{embedding_model}:{chunk_hash}因为同一段文本,用不同 embedding 模型生成的向量不能混用。模型变了,旧向量不是“稍微旧一点”,而是坐标系都可能换了。
命中率可以这样算:
embedding_hit_rate = cached_chunk_count / total_chunk_count
embedding_cost_saved = cached_chunk_tokens * embedding_price_per_token3. Retrieval 缓存
查询结果也可以短期缓存:
rag:retrieval:{tenant}:{index_version}:{query_hash}:{top_k}但这里要小心:
- index 更新后必须换
index_version - query rewrite 版本变化也要进 key
- 权限过滤必须进 key 或在缓存后再次过滤
- TTL 不宜太长
4. Context Pack 缓存
RAG 最后还会把检索片段拼成 prompt context。这个步骤也可能昂贵,因为要去重、排序、裁剪 token、加引用。
可以缓存:
rag:context:{retrieval_result_hash}:{template_version}:{token_budget}这样用户连续追问同一个文档主题时,不必每轮都重新组织上下文。
但最终回答通常不建议直接缓存太久。回答和用户问题、权限、时间、模型版本、输出风格都有关,盲目缓存很容易省了钱,亏了信任。
五、购买链路:缓存负责快,数据库负责真,MQ 负责排队
购买和秒杀是缓存系统的经典战场。
业务问题不是“Redis 怎么扣库存”,而是:
- 高峰期怎么不打爆数据库?
- 用户怎么不能重复买?
- 库存怎么不能超卖?
- 订单事实怎么可靠落库?
- 发券、通知、积分这些后续动作怎么异步处理?
- Redis 挂了怎么办?
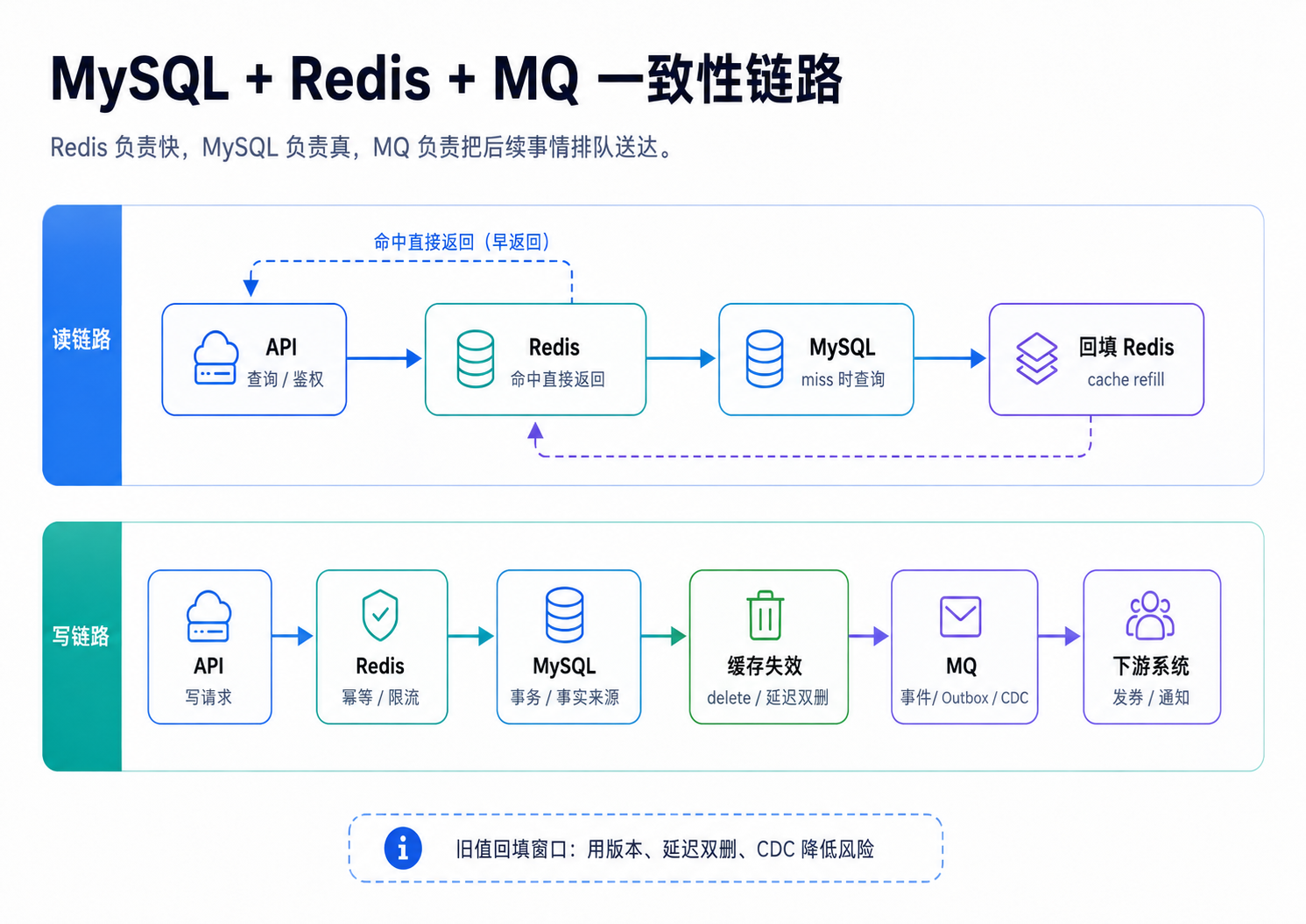
1. 读链路:商品详情缓存
商品详情适合 cache-aside:
读商品:
1. Go 本地缓存查前 N 秒热点
2. Redis 查商品详情
3. Redis miss 后查 MySQL
4. 回填 Redis,TTL 加随机抖动key:
product:detail:{product_id}:v{schema_version}TTL:
- 普通商品:5 到 30 分钟
- 活动商品:几十秒到几分钟
- 强运营实时变化字段:拆出来单独缓存或直接查源
为什么要 schema version?
因为缓存里的 JSON 结构迟早会变。没有版本,老缓存会像衣柜里的旧数据,平时看不见,线上突然穿出来吓人。
2. 写链路:订单事实先落库
订单、支付、库存流水这类事实,应该让 MySQL 负责。
Redis 可以做预扣和快速判断,但最终不能只靠 Redis 说“钱扣了”。
常见流程:
请求进来
-> Redis 限流
-> Redis SetNX 做幂等
-> Redis 预扣库存
-> MQ 投递创建订单事件
-> 消费者写 MySQL 订单事务
-> 成功后删除/刷新 Redis 商品缓存
-> MQ 通知发券、积分、短信关键点:
- 幂等 key 防按钮连点和重试
- 预扣失败直接返回库存不足
- MQ 消费者必须幂等,因为消息可能重复
- MySQL 订单表要有唯一约束,比如
(user_id, activity_id) - Redis 预扣和 MySQL 最终库存要有对账任务
3. 缓存不够时为什么要 MQ
缓存解决“快读快判定”。
MQ 解决“后续工作可靠排队”。
比如下单成功后:
- 发优惠券
- 发短信
- 通知仓储
- 写用户积分
- 写风控事件
- 预热推荐缓存
这些不应该都堵在用户请求里同步做。否则用户买一瓶水,要等仓库、短信、积分、风控全部开完会才拿到响应。
MQ 把这些动作拆出去。Redis 可以配合 MQ 做状态缓存、去重、短期事件索引,但不要把 Redis List 当专业 MQ 一路硬撑到业务变大。
六、Redis 和 MySQL 一致性:不要追求童话,追求可控
缓存一致性没有童话。
你能做的是把“不一致窗口”变短、变可观测、变可恢复。
1. 基础方案:写库后删缓存
更新商品:
1. 写 MySQL
2. 删除 Redis key为什么不是先删缓存再写库?
因为先删缓存后,另一个请求可能马上 miss,然后读到旧 MySQL 值并回填 Redis。你刚删完,它又把旧值请回来了。
为什么不是直接更新缓存?
因为缓存经常是聚合数据。你更新了商品主表字段,但缓存里可能还包含活动价、库存、标签、推荐分。直接更新很容易漏。
2. 旧值回填怎么处理
高并发下仍可能出现:
A 读缓存 miss
A 查 MySQL 旧值
B 写 MySQL 新值
B 删除缓存
A 把旧值写回 Redis解决组合:
- 缓存 value 带
version或updated_at - 回填前检查版本,新版本不被旧版本覆盖
- 写后延迟双删,降低旧值残留概率
- 用 binlog / CDC 订阅数据库变更,统一失效缓存
- 热点 key 回源加 singleflight / mutex
- TTL 不要过长
3. 什么时候不能靠缓存一致性
这些场景不要让 Redis 当最终裁判:
- 支付扣款
- 订单最终状态
- 库存财务结算
- 审计日志
- 权限授权最终结果
Redis 可以做快速拦截、预判、临时状态。最终事实应该在数据库事务或专门系统里。
Redis 的 WAIT 可以提高写入复制到副本的概率,在故障转移场景更稳一点;但它不会把 Redis 变成强一致数据库。
这句话很冷静,也很重要。
七、三大缓存问题:从面试题还原成业务事故
1. 缓存穿透:不存在的数据把数据库打穿
业务现场:
攻击者或错误客户端不断请求不存在的商品 ID:
/products/999999999999Redis 没有,MySQL 也没有。每次都查库。
解决方案:
- 参数校验:明显非法 ID 直接拒绝
- 缓存空值:
product:null:{id},TTL 短一点 - Bloom filter:快速判断 ID 是否可能存在
- 风控限流:异常模式直接限
Redis key:
product:null:{product_id} -> "1", TTL 60s注意:空值 TTL 不能太长。否则商品刚创建,用户还命中旧的“不存在”,运营同事会以为你在做行为艺术。
2. 缓存击穿:热点 key 过期,数据库被围观
业务现场:
一个爆款商品缓存过期,几万请求同时回源。
解决方案:
- 热点 key 提前预热
- 热点 key 逻辑过期:缓存不物理删除,后台异步刷新
- Go
singleflight合并单实例回源 - Redis 分布式锁合并跨实例回源
- 降级返回旧值
核心思想:
宁愿短时间返回稍旧数据,也不要让数据库当场表演原地升天。3. 缓存雪崩:一批 key 一起过期
业务现场:
活动商品统一设置 20:00 过期。到了 20:00,缓存集体下班,数据库集体加班。
解决方案:
- TTL 加随机抖动
- 分批预热
- 多级缓存
- 限流
- 降级
- 核心热点永不过期 + 后台刷新
func jitter(base time.Duration) time.Duration {
return base + time.Duration(rand.Intn(60))*time.Second
}八、排行榜:Redis ZSet 是现场大屏,不是赛后账本
排行榜适合 Redis,尤其是 ZSet。
比如游戏积分榜、直播热度榜、活动销售榜、热门 prompt 榜。
func addScore(ctx context.Context, rdb *redis.Client, userID int64, score float64) error {
return rdb.ZAdd(ctx, "rank:daily", redis.Z{
Score: score,
Member: userID,
}).Err()
}但排行榜业务不是只有 ZADD。
你要回答:
- 是实时榜还是结算榜?
- 分数能不能回滚?
- 跨服怎么合榜?
- 前 100 名是不是热点?
- 历史榜保存多久?
- 刷榜作弊怎么处理?
设计建议:
- Redis ZSet 维护实时榜
- MySQL / OLAP 存结算结果和历史榜
- 定时快照 Redis 榜单
- 大榜按赛区、活动、日期拆 key
- 前 N 名可做本地缓存,降低 Redis 热点
- 分数来源必须可追溯,不能只有 Redis 分数
key:
rank:{game}:{season}:{region}
rank_snapshot:{game}:{season}:{region}:{date}Redis 排行榜像现场大屏。
大屏要快,但奖金要看账本。你不能对财务说:“截图在这里,发钱吧。”
九、分布式 Redis:不是为了高级,是为了坏了还能活
单机 Redis 很舒服,直到它成为单点。
为什么需要分布式 Redis?
- 单机内存不够
- 单机 QPS 不够
- 单点故障不可接受
- 需要读扩展
- 需要自动故障转移
- 需要横向分片
1. 主从复制
主从复制解决冗余和读扩展。
但它不等于自动 failover。master 挂了,如果没有 Sentinel 或 Cluster,客户端不会自动知道谁是新 master。
2. Sentinel
Sentinel 适合“不需要分片,但需要高可用”的场景。
它负责:
- 监控 master 和 replica
- 判断 master 是否不可用
- 触发 failover
- 推选新 master
- 作为客户端配置发现来源
业务上要考虑:
- failover 期间短暂不可用怎么办?
- 客户端连接池如何刷新 master 地址?
- 写请求失败是否重试?
- 重试是否幂等?
- Redis 丢失少量最近写入是否可接受?
3. Cluster
Cluster 解决的是横向扩展和分片。
数据按 slot 分散到多个 master,每个 master 可以有 replica。
它适合:
- 数据量大
- QPS 高
- 单机扛不住
- key 可以良好分布
但 Cluster 也带来复杂度:
- multi-key 操作要考虑 hash slot
- 热 key 仍然可能打爆单节点
- 客户端要支持 MOVED/ASK 重定向
- 故障恢复要关注复制延迟和持久化
4. Redis 崩了怎么恢复
恢复不是一句“重启一下”。
你需要预案:
| 故障 | 系统动作 | 业务动作 |
|---|---|---|
| replica 崩 | 重启后重同步 | 读流量切走 |
| master 崩 | Sentinel/Cluster failover | 写请求短暂重试 |
| Redis 全挂 | 降级到 DB / 本地缓存 | 限流,保护数据库 |
| 数据丢失 | 从 AOF/RDB 或对账恢复 | 重建缓存,核对关键状态 |
| 热 key 打爆 | 拆 key / 本地缓存 / 限流 | 降级非核心字段 |
Redis 是缓存层时,核心能力是“可重建”。
如果某个 Redis key 丢了就业务不可恢复,那它可能根本不该只存在 Redis 里。
十、什么时候缓存不够,要加 MQ
缓存回答的是:
现在这个状态是什么?
MQ 回答的是:
这件事后面要让谁处理?
比如订单创建成功后:
- 发券
- 发短信
- 通知仓储
- 写积分
- 刷新推荐缓存
- 写审计
- 推送风控
这些动作如果都同步做,用户会觉得买东西像在等银行放款。
MQ 的价值:
- 削峰
- 解耦
- 重试
- 下游慢不拖主链路
- 事件广播
- 缓存失效通知
Redis Streams 可以当中轻量事件流,适合内部 worker、消费组、简单 ack。
但如果你需要:
- 大规模堆积
- 多业务主题治理
- 死信队列
- 严格消息保留
- 跨团队事件平台
就应该认真评估 Kafka、RabbitMQ、RocketMQ 等专业 MQ。
Redis 很好,但不要让它兼职所有中间件岗位。
十一、游戏缓存:WebSocket 棋盘和 UDP FPS 不是一种系统
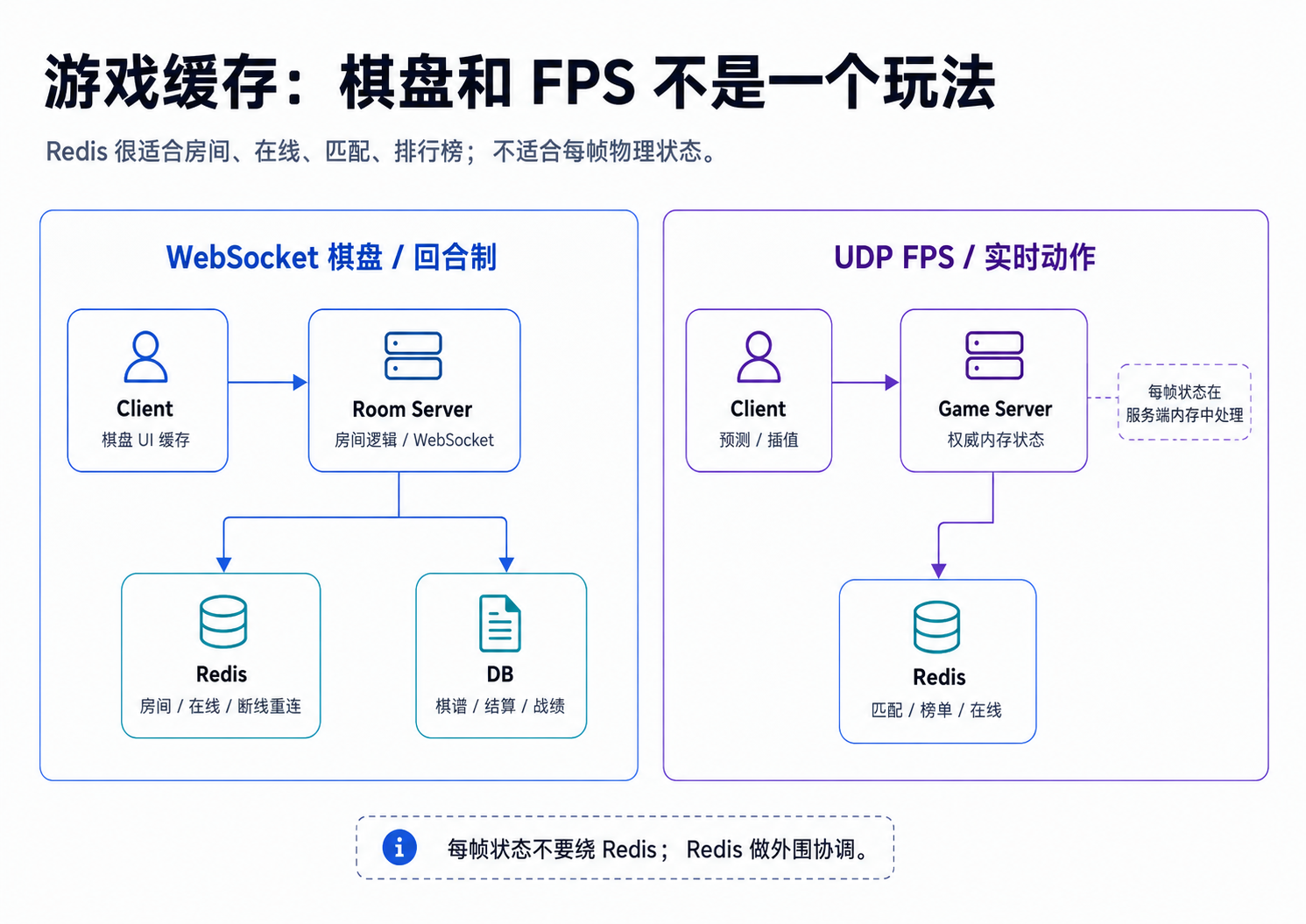
1. 棋盘 / 回合制游戏
比如五子棋、象棋、扑克房间。
特点:
- 状态变化频率低
- 顺序重要
- 每一步可以服务端校验
- WebSocket 很适合
缓存设计:
room:{room_id}:state Hash/String,当前房间状态
room:{room_id}:players Set,玩家列表
matchmaking:{mode} ZSet/List,匹配队列
presence:{user_id} String,在线状态 TTL
rank:{season}:{region} ZSet,排行榜落库:
- 棋谱
- 结算结果
- 积分变动
- 作弊审计
客户端可以缓存棋盘 UI,提升体验;但合法性要服务端判断。
客户端说“我赢了”,服务端不能直接鼓掌,还得看棋盘。
2. FPS / 实时动作游戏
FPS 是另一种生物。
特点:
- 状态高频变化
- 延迟极敏感
- UDP 或基于 UDP 的协议常见
- 服务端权威状态
- 客户端预测、插值、校正
Redis 不适合做:
- 每帧位置同步
- 子弹碰撞判定
- 实时物理状态
- 高频输入处理
Redis 适合做:
- 匹配
- 房间发现
- 在线状态
- 排行榜
- 战绩摘要
- 结算任务
- 跨服通知
FPS 的核心循环应该在游戏服务器内存里。Redis 是外围协调,不是帧同步心脏。
十二、最后给一个业务缓存设计清单
下次你想加缓存,不要先问“Redis key 怎么写”。
先问:
- 业务问题是什么?慢、贵、抖、不可恢复,还是数据库压力大?
- 这个数据是不是最终事实?
- 它丢了能不能重建?
- 它允许多久不一致?
- 它的命中 key 是什么?
- 这个 key 是否包含租户、权限、版本?
- TTL 怎么定?是否需要 jitter?
- miss 后谁回源?是否需要 singleflight / 锁?
- Redis 挂了怎么降级?
- 是否需要 MQ 承接后续动作?
- 是否需要记录 token、成本、命中率?
- 这个状态应该在客户端、Go 本地、Redis、向量库、Prompt Cache、MQ 还是数据库?
一个更成熟的缓存系统,不是 Redis 用得越多越好。
而是每一层都知道自己在解决什么:
- Go 本地缓存解决极低延迟和单实例热点
- Redis 解决跨实例热状态和协调
- Prompt Cache 解决模型前缀成本
- RAG cache 解决文档处理和检索成本
- MQ 解决异步和削峰
- MySQL 解决最终事实
- 客户端缓存解决交互体验
Redis 是非常重要的一层。
但业务系统真正需要的,不是“到处加 Redis”,而是:
让每个状态待在它最应该待的位置。